Publications
pySBOL3: SBOL3 for Python Programmers
The Synthetic Biology Open Language version 3 (SBOL3) provides a data model for representation of synthetic biology information across multiple scales and throughout the design-build-test-learn workflow. To support practical use of this data model, we have developed pySBOL3, a Python library that allows programmers to create and edit SBOL3 documents. Here we describe this library and key engineering decisions in its design. The resulting implementation is a compact and maintainable core that provides both a familiar, pythonic interface for manipulating SBOL3 objects as well as mechanisms for building additional extensions and representations on this base.
Virtual Parts Repository 2: Model-Driven Design of Genetic Regulatory Circuits
Engineering genetic regulatory circuits is key to the creation of biological applications that are responsive to environmental changes. Computational models can assist in understanding especially large and complex circuits for which manual analysis is infeasible, permitting a model-driven design process. However, there are still few tools that offer the ability to simulate the system under design. One of the reasons for this is the lack of accessible model repositories or libraries that cater to the modular composition of models of synthetic systems. Here, we present the second version of the Virtual Parts Repository, a framework to facilitate the model-driven design of genetic regulatory circuits, which provides reusable, modular, and composable models. The new framework is service-oriented, easier to use in computational workflows, and provides several new features and access methods. New features include supporting hierarchical designs via a graph-based repository or compatible remote repositories, enriching existing designs, and using designs provided in Synthetic Biology Open Language documents to derive system-scale and hierarchical Systems Biology Markup Language models. We also present a reaction-based modeling abstraction inspired by rule-based modeling techniques to facilitate scalable and modular modeling of complex and large designs. This modeling abstraction enhances the modeling capability of the framework, for example, to incorporate design patterns such as roadblocking, distributed deployment of genetic circuits using plasmids, and cellular resource dependency. The framework and the modeling abstraction presented in this paper allow computational design tools to take advantage of computational simulations and ultimately help facilitate more predictable applications.
Intent Parser: A Tool for Codification and Sharing of Experimental Design
Communicating information about experimental design among a team of collaborators is challenging because different people tend to describe experiments in different ways and with different levels of detail. Sometimes, humans can interpret missing information by making assumptions and drawing inferences from information already provided. Doing so, however, is error-prone and typically requires a high level of interpersonal communication. In this paper, we present a tool that addresses this challenge by providing a simple interface for incremental formal codification of experiment designs. Users interact with a Google Docs word-processing interface with structured tables, backed by assisted linking to machine-readable definitions in a data repository (SynBioHub) and specification of available protocols and requests for execution in the Open Protocol Interface Language (OPIL). The result is an easy-to-use tool for generating machine-readable descriptions of experiment designs with which users in the DARPA SD2 program have collected data from 80 208 samples using a variety of protocols and instruments over the course of 181 experiment runs.
Synthetic Biology Curation Tools (SYNBICT)
Much progress has been made in developing tools to generate component-based design representations of biological systems from standard libraries of parts. Most biological designs, however, are still specified at the sequence level. Consequently, there exists a need for a tool that can be used to automatically infer component-based design representations from sequences, particularly in cases when those sequences have minimal levels of annotation. Such a tool would assist computational synthetic biologists in bridging the gap between the outputs of sequence editors and the inputs to more sophisticated design tools, and it would facilitate their development of automated workflows for design curation and quality control. Accordingly, we introduce Synthetic Biology Curation Tools (SYNBICT), a Python tool suite for automation-assisted annotation, curation, and functional inference for genetic designs. We have validated SYNBICT by applying it to genetic designs in the DARPA Synergistic Discovery & Design (SD2) program and the International Genetically Engineered Machines (iGEM) 2018 distribution. Most notably, SYNBICT is more automated and parallelizable than manual design editors, and it can be applied to interpret existing designs instead of only generating new ones.
Synthetic Biology Open Language Visual (SBOL Visual) Version 3.0
People who engineer biological organisms often find it useful to draw diagrams in order to communicate both the structure of the nucleic acid sequences that they are engineering and the functional relationships between sequence features and other molecular species. Some typical practices and conventions have begun to emerge for such diagrams. SBOL Visual aims to organize and systematize such conventions in order to produce a coherent language for expressing the structure and function of genetic designs. This document details version 3.0 of SBOL Visual, a new major revision of the standard. The major difference between SBOL Visual 3 and SBOL Visual 2 is that diagrams and glyphs are defined with respect to the SBOL 3 data model rather than the SBOL 2 data model. A byproduct of this change is that the use of dashed undirected lines for subsystem mappings has been removed, pending future determination on how to represent general SBOL 3 constraints; in the interim, this annotation can still be used as an annotation. Finally, deprecated material has been removed from collection of glyphs: the deprecated insulator'' glyph and macromolecule’’ alternative glyphs have been removed, as have the deprecated BioPAX alternatives to SBO terms.
Stochastic Hazard Analysis of Genetic Circuits in iBioSim and STAMINA
In synthetic biology, combinational circuits are used to program cells for various new applications like biosensors, drug delivery systems, and biofuels. Similar to asynchronous electronic circuits, some combinational genetic circuits may show unwanted switching variations (glitches) caused by multiple input changes. Depending on the biological circuit, glitches can cause irreversible effects and jeopardize the circuit’s functionality. This paper presents a stochastic analysis to predict glitch propensities for three implementations of a genetic circuit with known glitching behavior. The analysis uses STochastic Approximate Model-checker for INfinite-state Analysis (STAMINA), a tool for stochastic verification. The STAMINA results were validated by comparison to stochastic simulation in iBioSim resulting in further improvements of STAMINA. This paper demonstrates that stochastic verification can be utilized by genetic designers to evaluate design choices and input restrictions to achieve a desired reliability of operation.
Curation Principles Derived from the Analysis of the SBOL iGEM Data Set
As an engineering endeavor, synthetic biology requires effective sharing of genetic design information that can be reused in the construction of new designs. While there are a number of large community repositories of design information, curation of this information has been limited. This in turn limits the ways in which design information can be put to use. The aim of this work was to improve this situation by creating a curated library of parts from the International Genetically Engineered Machines (iGEM) registry data set. To this end, an analysis of the Synthetic Biology Open Language (SBOL) version of the iGEM registry was carried out using four different approaches-simple statistics, SnapGene autoannotation, SYNBICT autoannotation, and expert analysis-the results of which are presented herein. Key challenges encountered include the use of free text, insufficient part provenance, part duplication, lack of part removal, and insufficient continuous curation. On the basis of these analyses, the focus has shifted from the creation of a curated iGEM part library to instead the extraction of a set of lessons, which are presented here. These lessons can be exploited to facilitate the creation and curation of other part libraries using a simpler and less labor intensive process.
BioParts—A Biological Parts Search Portal and Updates to the ICE Parts Registry Software Platform
Capturing, storing, and sharing biological DNA parts data are integral parts of synthetic biology research. Here, we detail updates to the ICE biological parts registry software platform that enable these processes, describe our implementation of the Web of Registries concept using ICE, and establish Bioparts, a search portal for biological parts available in the public domain. The Web of Registries enables standalone ICE installations to securely connect and form a distributed parts database. This distributed database allows users from one registry to query and access plasmid, strain, (DNA) part, plant seed, and protein entry types in other connected registries. Users can also transfer entries from one ICE registry to another or make them publicly accessible. Bioparts, the new search portal, combines the ease and convenience of modern web search engines with the capabilities of bioinformatics search tools such as BLAST. This portal, available at bioparts.org, allows anyone to search for publicly accessible biological part information (e.g., NCBI, iGEM, SynBioHub, Addgene), including parts publicly accessible through ICE Registries. Additionally, the portal offers a REST API that enables third-party applications and tools to access the portal’s functionality programmatically.
VisBOL2—Improving Web-Based Visualization for Synthetic Biology Designs
VisBOL is a web-based visualization tool used to depict genetic circuit designs. This tool depicts simple DNA circuits adequately, but it has become increasingly outdated as new versions of SBOL Visual were released. This paper introduces VisBOL2, a heavily redesigned version of VisBOL that makes a number of improvements to the original VisBOL, including proper functional interaction rendering, dynamic viewing, a more maintainable code base, and modularity that facilitates compatibility with other software tools. This modularity is demonstrated by incorporating VisBOL2 into a sequence visualization plugin for SynBioHub.
Toward Full-Stack In Silico Synthetic Biology: Integrating Model Specification, Simulation, Verification, and Biological Compilation
We present the Infobiotics Workbench (IBW), a user-friendly, scalable, and integrated computational environment for the computer-aided design of synthetic biological systems. It supports an iterative workflow that begins with specification of the desired synthetic system, followed by simulation and verification of the system in high-performance environments and ending with the eventual compilation of the system specification into suitable genetic constructs. IBW integrates modeling, simulation, verification, and biocompilation features into a single software suite. This integration is achieved through a new domain-specific biological programming language, the Infobiotics Language (IBL), which tightly combines these different aspects of in silico synthetic biology into a full-stack integrated development environment. Unlike existing synthetic biology modeling or specification languages, IBL uniquely blends modeling, verification, and biocompilation statements into a single file. This allows biologists to incorporate design constraints within the specification file rather than using decoupled and independent formalisms for different in silico analyses. This novel approach offers seamless interoperability across different tools as well as compatibility with SBOL and SBML frameworks and removes the burden of doing manual translations for standalone applications. We demonstrate the features, usability, and effectiveness of IBW and IBL using well-established synthetic biological circuits.
Synthetic Biology Knowledge System
The Synthetic Biology Knowledge System (SBKS) is an instance of the SynBioHub repository that includes text and data information that has been mined from papers published in ACS Synthetic Biology. This paper describes the SBKS curation framework that is being developed to construct the knowledge stored in this repository. The text mining pipeline performs automatic annotation of the articles using natural language processing techniques to identify salient content such as key terms, relationships between terms, and main topics. The data mining pipeline performs automatic annotation of the sequences extracted from the supplemental documents with the genetic parts used in them. Together these two pipelines link genetic parts to papers describing the context in which they are used. Ultimately, SBKS will reduce the time necessary for synthetic biologists to find the information necessary to complete their designs.
Synthetic Biology Open Language Visual (SBOL Visual) Version 2.3
People who are engineering biological organisms often find it useful to communicate in diagrams, both about the structure of the nucleic acid sequences that they are engineering and about the functional relationships between sequence features and other molecular species. Some typical practices and conventions have begun to emerge for such diagrams. The Synthetic Biology Open Language Visual (SBOL Visual) has been developed as a standard for organizing and systematizing such conventions in order to produce a coherent language for expressing the structure and function of genetic designs. This document details version 2.3 of SBOL Visual, which builds on the prior SBOL Visual 2.2 in several ways. First, the specification now includes higher-level interactions with interactions,'' such as an inducer molecule stimulating a repression interaction. Second, binding with a nucleic acid backbone can be shown by overlapping glyphs, as with other molecular complexes. Finally, a new unspecified interaction’’ glyph is added for visualizing interactions whose nature is unknown, the insulator'' glyph is deprecated in favor of a new inert DNA spacer’’ glyph, and the polypeptide region glyph is recommended for showing 2A sequences.
SBOLCanvas: A Visual Editor for Genetic Designs
SBOLCanvas is a web-based application that can create and edit genetic constructs using the SBOL data and visual standards. SBOLCanvas allows a user to create a genetic design visually and structurally from start to finish. It also allows users to incorporate existing SBOL data from a SynBioHub repository. By the nature of being a web-based application, SBOLCanvas is readily accessible and easy to use. A live version of the latest release can be found at https://sbolcanvas.org.
paraSBOLv: A Foundation for Standard-Compliant Genetic Design Visualization Tools
Diagrams constructed from standardized glyphs are central to communicating complex design information in many engineering fields. For example, circuit diagrams are commonplace in electronics and allow for a suitable abstraction of the physical system that helps support the design process. With the development of the Synthetic Biology Open Language Visual (SBOLv), bioengineers are now positioned to better describe and share their biological designs visually. However, the development of computational tools to support the creation of these diagrams is currently hampered by an excessive burden in maintenance due to the large and expanding number of glyphs present in the standard. Here, we present a Python package called paraSBOLv that enables access to the full suite of SBOLv glyphs through the use of machine-readable parametric glyph definitions. These greatly simplify the rendering process while allowing extensive customization of the resulting diagrams. We demonstrate how the adoption of paraSBOLv can accelerate the development of highly specialized biodesign visualization tools or even form the basis for more complex software by removing the burden of maintaining glyph-specific rendering code. Looking forward, we suggest that incorporation of machine-readable parametric glyph definitions into the SBOLv standard could further simplify the development of tools to produce standard-compliant diagrams and the integration of visual standards across fields.
Flapjack: Data Management and Analysis for Genetic Circuit Characterization
Characterization is fundamental to the design, build, test, learn (DBTL) cycle for engineering synthetic genetic circuits. Components must be described in such a way as to account for their behavior in a range of contexts. Measurements and associated metadata, including part composition, constitute the test phase of the DBTL cycle. These data may consist of measurements of thousands of circuits, measured in hundreds of conditions, in multiple assays potentially performed in different laboratories and using different techniques. In order to inform the learn phase this large volume of data must be filtered, collated, and analyzed. Characterization consists of using this data to parametrize models of component function in different contexts, and combining them to predict behaviors of novel circuits. Tools to store, organize, share, and analyze large volumes of measurement and metadata are therefore essential to linking the test phase to the build and learn phases, closing the loop of the DBTL cycle. Here we present such a system, implemented as a web app with a backend data registry and analysis engine. An interactive frontend provides powerful querying, plotting, and analysis tools, and we provide a REST API and Python package for full integration with external build and learn software. All measurements are associated with circuit part composition via SBOL (Synthetic Biology Open Language). We demonstrate our tool by characterizing a range of genetic components and circuits according to composition and context.
Genetic Circuit Dynamics: Hazard and Glitch Analysis
Multiple input changes can cause unwanted switching variations, or glitches, in the output of genetic combinational circuits. These glitches can have drastic effects if the output of the circuit causes irreversible changes within or with other cells such as a cascade of responses, apoptosis, or the release of a pharmaceutical in an off-target tissue. Therefore, avoiding unwanted variation of a circuit’s output can be crucial for the safe operation of a genetic circuit. This paper investigates what causes unwanted switching variations in combinational genetic circuits using hazard analysis and a new dynamic model generator. The analysis is done in previously built and modeled genetic circuits with known glitching behavior. The dynamic models generated not only predict the same steady states as previous models but can also predict the unwanted switching variations that have been observed experimentally. Multiple input changes may cause glitches due to propagation delays within the circuit. Modifying the circuit’s layout to alter these delays may change the likelihood of certain glitches, but it cannot eliminate the possibility that the glitch may occur. In other words, function hazards cannot be eliminated. Instead, they must be avoided by restricting the allowed input changes to the system. Logic hazards, on the other hand, can be avoided using hazard-free logic synthesis. This paper demonstrates this by showing how a circuit designed using a popular genetic design automation tool can be redesigned to eliminate logic hazards.
Capturing Multicellular System Designs Using Synthetic Biology Open Language (SBOL)
Synthetic biology aims to develop novel biological systems and increase their reproducibility using engineering principles such as standardization and modularization. It is important that these systems can be represented and shared in a standard way to ensure they can be easily understood, reproduced, and utilized by other researchers. The Synthetic Biology Open Language (SBOL) is a data standard for sharing biological designs and information about their implementation and characterization. Previously, this standard has only been used to represent designs in systems where the same design is implemented in every cell; however, there is also much interest in multicellular systems, in which designs involve a mixture of different types of cells with differing genotype and phenotype. Here, we show how the SBOL standard can be used to represent multicellular systems, and, hence, how researchers can better share designs with the community and reliably document intended system functionality.
Synthetic Biology Open Language Visual (SBOL Visual) Version 2.2
People who are engineering biological organisms often find it useful to communicate in diagrams, both about the structure of the nucleic acid sequences that they are engineering and about the functional relationships between sequence features and other molecular species. Some typical practices and conventions have begun to emerge for such diagrams. The Synthetic Biology Open Language Visual (SBOL Visual) has been developed as a standard for organizing and systematizing such conventions in order to produce a coherent language for expressing the structure and function of genetic designs. This document details version 2.2 of SBOL Visual, which builds on the prior SBOL Visual 2.1 in several ways. First, the grounding of molecular species glyphs is changed from BioPAX to SBO, aligning with the use of SBO terms for interaction glyphs. Second, new glyphs are added for proteins, introns, and polypeptide regions (e.~g., protein domains), the prior recommended macromolecule glyph is deprecated in favor of its alternative, and small polygons are introduced as alternative glyphs for simple chemicals.
Extending SynBioHub's Functionality with Plugins
SynBioHub is a repository for synthetic genetic designs represented in the Synthetic Biology Open Language (SBOL). To integrate SynBioHub into more synthetic biology workflows, its data processing capabilities need to be expanded. To this end, a plugin interface has been developed. Plugins can be developed for data submission, visualization, and download. This framework was tested by the development of three example plugins, one of each type as follows: one allowing the submission of SnapGene files, one visualizing the course of different genetic parts, and one preparing plasmid maps for download.
SBOL Visual 2 Ontology
Standardizing the visual representation of genetic parts and circuits is essential for unambiguously creating and interpreting genetic designs. To this end, an increasing number of tools are adopting well-defined glyphs from the Synthetic Biology Open Language (SBOL) Visual standard to represent various genetic parts and their relationships. However, the implementation and maintenance of the relationships between biological elements or concepts and their associated glyphs has up to now been left up to tool developers. We address this need with the SBOL Visual 2 Ontology, a machine-accessible resource that provides rules for mapping from genetic parts, molecules, and interactions between them, to agreed SBOL Visual glyphs. This resource, together with a web service, can be used as a library to simplify the development of visualization tools, as a stand-alone resource to computationally search for suitable glyphs, and to help facilitate integration with existing biological ontologies and standards in synthetic biology.
Synthetic biology open language visual (SBOL visual) version 2.2
People who are engineering biological organisms often find it useful to communicate in diagrams, both about the structure of the nucleic acid sequences that they are engineering and about the functional relationships between sequence features and other molecular species. Some typical practices and conventions have begun to emerge for such diagrams. The Synthetic Biology Open Language Visual (SBOL Visual) has been developed as a standard for organizing and systematizing such conventions in order to produce a coherent language for expressing the structure and function of genetic designs. This document details version 2.2 of SBOL Visual, which builds on the prior SBOL Visual 2.1 in several ways. First, the grounding of molecular species glyphs is changed from BioPAX to SBO, aligning with the use of SBO terms for interaction glyphs. Second, new glyphs are added for proteins, introns, and polypeptide regions (e. g., protein domains), the prior recommended macromolecule glyph is deprecated in favor of its alternative, and small polygons are introduced as alternative glyphs for simple chemicals.
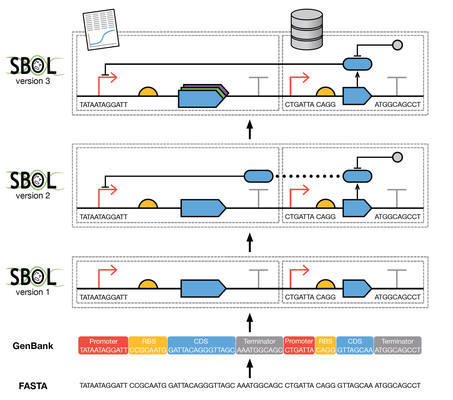
Synthetic biology open language (SBOL) version 3.0.0
Synthetic biology builds upon genetics, molecular biology, and metabolic engineering by applying engineering principles to the design of biological systems. When designing a synthetic system, synthetic biologists need to exchange information about multiple types of molecules, the intended behavior of the system, and actual experimental measurements. The Synthetic Biology Open Language (SBOL) has been developed as a standard to support the specification and exchange of biological design information in synthetic biology, following an open community process involving both wet bench scientists and dry scientific modelers and software developers, across academia, industry, and other institutions. This document describes SBOL 3.0.0, which condenses and simplifies previous versions of SBOL based on experiences in deployment across a variety of scientific and industrial settings. In particular, SBOL 3.0.0, (1) separates sequence features from part/sub-part relationships, (2) renames Component Definition/Component to Component/Sub-Component, (3) merges Component and Module classes, (4) ensures consistency between data model and ontology terms, (5) extends the means to define and reference Sub-Components, (6) refines requirements on object URIs, (7) enables graph-based serialization, (8) moves Systems Biology Ontology (SBO) for Component types, (9) makes all sequence associations explicit, (10) makes interfaces explicit, (11) generalizes Sequence Constraints into a general structural Constraint class, and (12) expands the set of allowed constraints.
ShortBOL: A Language for Scripting Designs for Engineered Biological Systems Using Synthetic Biology Open Language (SBOL)
The Synthetic Biology Open Language (SBOL) is an emerging synthetic biology data exchange standard, designed primarily for unambiguous and efficient machine-to-machine communication. However, manual editing of SBOL is generally difficult for nontrivial designs. Here, we describe ShortBOL, a lightweight SBOL scripting language that bridges the gap between manual editing, visual design tools, and direct programming. ShortBOL is a shorthand textual language developed to enable users to create SBOL designs quickly and easily, without requiring strong programming skills or visual design tools.
SBOL Visual 2 Ontology
Standardizing the visual representation of genetic parts and circuits is essential for unambiguously creating and interpreting genetic designs. To this end, an increasing number of tools are adopting well-defined glyphs from the Synthetic Biology Open Language (SBOL) Visual standard to represent various genetic parts and their relationships. However, the implementation and maintenance of the relationships between biological elements or concepts and their associated glyphs has up to now been left up to tool developers. We address this need with the SBOL Visual 2 Ontology, a machine-accessible resource that provides rules for mapping from genetic parts, molecules, and interactions between them, to agreed SBOL Visual glyphs. This resource, together with a web service, can be used as a library to simplify the development of visualization tools, as a stand-alone resource to computationally search for suitable glyphs, and to help facilitate integration with existing biological ontologies and standards in synthetic biology.
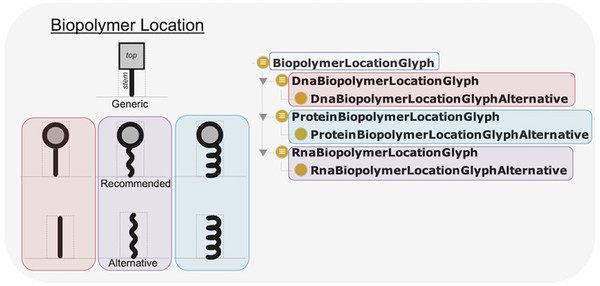
SBOL Visual 2 Ontology
Standardizing the visual representation of genetic parts and circuits is essential for unambiguously creating and interpreting genetic designs. To this end, an increasing number of tools are adopting well-defined glyphs from the Synthetic Biology Open Language (SBOL) Visual standard to represent various genetic parts and their relationships. However, the implementation and maintenance of the relationships between biological elements or concepts and their associated glyphs has up to now been left up to tool developers. We address this need with the SBOL Visual 2 Ontology, a machine-accessible resource that provides rules for mapping from genetic parts, molecules, and interactions between them, to agreed SBOL Visual glyphs. This resource, together with a web service, can be used as a library to simplify the development of visualization tools, as a stand-alone resource to computationally search for suitable glyphs, and to help facilitate integration with existing biological ontologies and standards in synthetic biology.
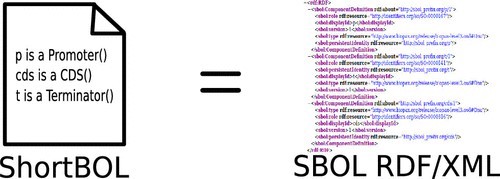
ShortBOL: A Language for Scripting Designs for Engineered Biological Systems Using Synthetic Biology Open Language (SBOL)
The Synthetic Biology Open Language (SBOL) is an emerging synthetic biology data exchange standard, designed primarily for unambiguous and efficient machine-to-machine communication. However, manual editing of SBOL is generally difficult for nontrivial designs. Here, we describe ShortBOL, a lightweight SBOL scripting language that bridges the gap between manual editing, visual design tools, and direct programming. ShortBOL is a shorthand textual language developed to enable users to create SBOL designs quickly and easily, without requiring strong programming skills or visual design tools.
The Synthetic Biology Open Language (SBOL) Version 3: Simplified Data Exchange for Bioengineering
The Synthetic Biology Open Language (SBOL) is a community-developed data standard that allows knowledge about biological designs to be captured using a machine-tractable, ontology-backed representation that is built using Semantic Web technologies. While early versions of SBOL focused only on the description of DNA-based components and their sub-components, SBOL can now be used to represent knowledge across multiple scales and throughout the entire synthetic biology workflow, from the specification of a single molecule or DNA fragment through to multicellular systems containing multiple interacting genetic circuits. The third major iteration of the SBOL standard, SBOL3, is an effort to streamline and simplify the underlying data model with a focus on real-world applications, based on experience from the deployment of SBOL in a variety of scientific and industrial settings. Here, we introduce the SBOL3 specification both in comparison to previous versions of SBOL and through practical examples of its use.
The Synthetic Biology Open Language (SBOL) Version 3: Simplified Data Exchange for Bioengineering
The Synthetic Biology Open Language (SBOL) is a community-developed data standard that allows knowledge about biological designs to be captured using a machine-tractable, ontology-backed representation that is built using Semantic Web technologies. While early versions of SBOL focused only on the description of DNA-based components and their sub-components, SBOL can now be used to represent knowledge across multiple scales and throughout the entire synthetic biology workflow, from the specification of a single molecule or DNA fragment through to multicellular systems containing multiple interacting genetic circuits. The third major iteration of the SBOL standard, SBOL3, is an effort to streamline and simplify the underlying data model with a focus on real-world applications, based on experience from the deployment of SBOL in a variety of scientific and industrial settings. Here, we introduce the SBOL3 specification both in comparison to previous versions of SBOL and through practical examples of its use.
Communicating Structure and Function in Synthetic Biology Diagrams
Biological engineers often find it useful to communicate using diagrams. These diagrams can include information both about the structure of the nucleic acid sequences they are engineering and about the functional relationships between features of these sequences and/or other molecular species. A number of conventions and practices have begun to emerge within synthetic biology for creating such diagrams, and the Synthetic Biology Open Language Visual (SBOL Visual) has been developed as a standard to organize, systematize, and extend such conventions in order to produce a coherent visual language. Here, we describe SBOL Visual version 2, which expands previous diagram standards to include new functional interactions, categories of molecular species, support for families of glyph variants, and the ability to indicate modular structure and mappings between elements of a system. SBOL Visual 2 also clarifies a number of requirements and best practices, significantly expands the collection of glyphs available to describe genetic features, and can be readily applied using a wide variety of software tools, both general and bespoke.
Communicating Structure and Function in Synthetic Biology Diagrams
Biological engineers often find it useful to communicate using diagrams. These diagrams can include information both about the structure of the nucleic acid sequences they are engineering and about the functional relationships between features of these sequences and/or other molecular species. A number of conventions and practices have begun to emerge within synthetic biology for creating such diagrams, and the Synthetic Biology Open Language Visual (SBOL Visual) has been developed as a standard to organize, systematize, and extend such conventions in order to produce a coherent visual language. Here, we describe SBOL Visual version 2, which expands previous diagram standards to include new functional interactions, categories of molecular species, support for families of glyph variants, and the ability to indicate modular structure and mappings between elements of a system. SBOL Visual 2 also clarifies a number of requirements and best practices, significantly expands the collection of glyphs available to describe genetic features, and can be readily applied using a wide variety of software tools, both general and bespoke.
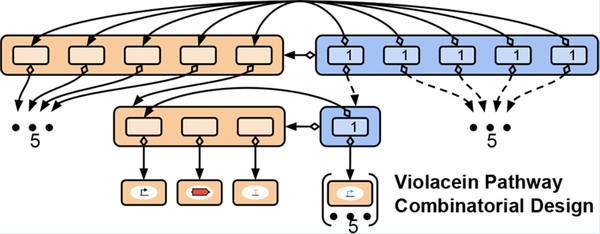
Specifying Combinatorial Designs with the Synthetic Biology Open Language (SBOL)
As improvements in DNA synthesis technology and assembly methods make combinatorial assembly of genetic constructs increasingly accessible, methods for representing genetic constructs likewise need to improve to handle the exponential growth of combinatorial design space. To this end, we present a community accepted extension of the SBOL data standard that allows for the efficient and flexible encoding of combinatorial designs. This extension includes data structures for representing genetic designs with “variable” components that can be implemented by choosing one of many linked designs for existing genetic parts or constructs. We demonstrate the representational power of the SBOL combinatorial design extension through case studies on metabolic pathway design and genetic circuit design, and we report the expansion of the SBOLDesigner software tool to support users in creating and modifying combinatorial designs in SBOL.
SBOL-OWL: An Ontological Approach for Formal and Semantic Representation of Synthetic Biology Information
Standard representation of data is key for the reproducibility of designs in synthetic biology. The Synthetic Biology Open Language (SBOL) has already emerged as a data standard to represent information about genetic circuits, and it is based on capturing data using graphs. The language provides the syntax using a free text document that is accessible to humans only. This paper describes SBOL-OWL, an ontology for a machine understandable definition of SBOL. This ontology acts as a semantic layer for genetic circuit designs. As a result, computational tools can understand the meaning of design entities in addition to parsing structured SBOL data. SBOL-OWL not only describes how genetic circuits can be constructed computationally, it also facilitates the use of several existing Semantic Web tools for synthetic biology. This paper demonstrates some of these features, for example, to validate designs and check for inconsistencies. Through the use of SBOL-OWL, queries can be simplified and become more intuitive. Moreover, existing reasoners can be used to infer information about genetic circuit designs that cannot be directly retrieved using existing querying mechanisms. This ontological representation of the SBOL standard provides a new perspective to the verification, representation, and querying of information about genetic circuits and is important to incorporate complex design information via the integration of biological ontologies.
pySBOL: A Python Package for Genetic Design Automation and Standardization
This paper presents pySBOL, a software library for computer-aided design of synthetic biological systems in the Python scripting language. This library provides an easy-to-use, object-oriented, application programming interface (API) with low barrier of entry for synthetic biology application developers. The pySBOL library enables reuse of genetic parts and designs through standardized data exchange with biological parts repositories and software tools that communicate using the Synthetic Biology Open Language (SBOL). In addition, pySBOL supports data management of design-build-test-learn workflows for individual laboratories as well as large, distributed teams of synthetic biologists. PySBOL also lets users add custom data to SBOL files to support the specific data requirements of their research. This extensibility helps users integrate software tool chains and develop workflows for new applications. These features and others make the pySBOL library a valuable tool for supporting engineering practices in synthetic biology. Documentation and installation instructions can be found at pysbol2.readthedocs.io.
A Computational Workflow for the Automated Generation of Models of Genetic Designs
Computational models are essential to engineer predictable biological systems and to scale up this process for complex systems. Computational modeling often requires expert knowledge and data to build models. Clearly, manual creation of models is not scalable for large designs. Despite several automated model construction approaches, computational methodologies to bridge knowledge in design repositories and the process of creating computational models have still not been established. This paper describes a workflow for automatic generation of computational models of genetic circuits from data stored in design repositories using existing standards. This workflow leverages the software tool SBOLDesigner to build structural models that are then enriched by the Virtual Parts Repository API using Systems Biology Open Language (SBOL) data fetched from the SynBioHub design repository. The iBioSim software tool is then utilized to convert this SBOL description into a computational model encoded using the Systems Biology Markup Language (SBML). Finally, this SBML model can be simulated using a variety of methods. This workflow provides synthetic biologists with easy to use tools to create predictable biological systems, hiding away the complexity of building computational models. This approach can further be incorporated into other computational workflows for design automation.
Specifying Combinatorial Designs with the Synthetic Biology Open Language (SBOL)
As improvements in DNA synthesis technology and assembly methods make combinatorial assembly of genetic constructs increasingly accessible, methods for representing genetic constructs likewise need to improve to handle the exponential growth of combinatorial design space. To this end, we present a community accepted extension of the SBOL data standard that allows for the efficient and flexible encoding of combinatorial designs. This extension includes data structures for representing genetic designs with ``variable’’ components that can be implemented by choosing one of many linked designs for existing genetic parts or constructs. We demonstrate the representational power of the SBOL combinatorial design extension through case studies on metabolic pathway design and genetic circuit design, and we report the expansion of the SBOLDesigner software tool to support users in creating and modifying combinatorial designs in SBOL.
Specifications of Standards in Systems and Synthetic Biology: Status and Developments in 2019
This special issue of the Journal of Integrative Bioinformatics presents an overview of COMBINE standards and their latest specifications. The standards cover representation formats for computational modeling in synthetic and systems biology and include BioPAX, CellML, NeuroML, SBML, SBGN, SBOL and SED-ML. The articles in this issue contain updated specifications of SBGN Process Description Level 1 Version 2, SBML Level 3 Core Version 2 Release 2, SBOL Version 2.3.0, and SBOL Visual Version 2.1.
SBOL-OWL: An Ontological Approach for Formal and Semantic Representation of Synthetic Biology Information
Standard representation of data is key for the reproducibility of designs in synthetic biology. The Synthetic Biology Open Language (SBOL) has already emerged as a data standard to represent information about genetic circuits, and it is based on capturing data using graphs. The language provides the syntax using a free text document that is accessible to humans only. This paper describes SBOL-OWL, an ontology for a machine understandable definition of SBOL. This ontology acts as a semantic layer for genetic circuit designs. As a result, computational tools can understand the meaning of design entities in addition to parsing structured SBOL data. SBOL-OWL not only describes how genetic circuits can be constructed computationally, it also facilitates the use of several existing Semantic Web tools for synthetic biology. This paper demonstrates some of these features, for example, to validate designs and check for inconsistencies. Through the use of SBOL-OWL, queries can be simplified and become more intuitive. Moreover, existing reasoners can be used to infer information about genetic circuit designs that cannot be directly retrieved using existing querying mechanisms. This ontological representation of the SBOL standard provides a new perspective to the verification, representation, and querying of information about genetic circuits and is important to incorporate complex design information via the integration of biological ontologies.
pySBOL: A Python Package for Genetic Design Automation and Standardization
This paper presents pySBOL, a software library for computer-aided design of synthetic biological systems in the Python scripting language. This library provides an easy-to-use, object-oriented, application programming interface (API) with low barrier of entry for synthetic biology application developers. The pySBOL library enables reuse of genetic parts and designs through standardized data exchange with biological parts repositories and software tools that communicate using the Synthetic Biology Open Language (SBOL). In addition, pySBOL supports data management of design-build-test-learn workflows for individual laboratories as well as large, distributed teams of synthetic biologists. PySBOL also lets users add custom data to SBOL files to support the specific data requirements of their research. This extensibility helps users integrate software tool chains and develop workflows for new applications. These features and others make the pySBOL library a valuable tool for supporting engineering practices in synthetic biology. Documentation and installation instructions can be found at pysbol2.readthedocs.io.
Design of Asynchronous Genetic Circuits
Most digital electronic circuits utilize a timing reference to synchronize the progression of signals and enable sequential memory elements. These designs may not be realizable in biological substrates due to the lack of a reliable high-frequency clock signal. Asynchronous designs eliminate the need for a clock with data encodings and request/acknowledge handshake protocols. This paper proposes a workflow to automate the design of asynchronous genetic circuits. This workflow extends genetic design tools by leveraging asynchronous logic design methods customized for this technology. This workflow is demonstrated on a genetic sensor that uses filtering and cellular communication to improve its reliability.
Design of Asynchronous Genetic Circuits
Most digital electronic circuits utilize a timing reference to synchronize the progression of signals and enable sequential memory elements. These designs may not be realizable in biological substrates due to the lack of a reliable high-frequency clock signal. Asynchronous designs eliminate the need for a clock with data encodings and request/acknowledge handshake protocols. This paper proposes a workflow to automate the design of asynchronous genetic circuits. This workflow extends genetic design tools by leveraging asynchronous logic design methods customized for this technology. This workflow is demonstrated on a genetic sensor that uses filtering and cellular communication to improve its reliability.
A Computational Workflow for the Automated Generation of Models of Genetic Designs
Computational models are essential to engineer predictable biological systems and to scale up this process for complex systems. Computational modeling often requires expert knowledge and data to build models. Clearly, manual creation of models is not scalable for large designs. Despite several automated model construction approaches, computational methodologies to bridge knowledge in design repositories and the process of creating computational models have still not been established. This paper describes a workflow for automatic generation of computational models of genetic circuits from data stored in design repositories using existing standards. This workflow leverages the software tool SBOLDesigner to build structural models that are then enriched by the Virtual Parts Repository API using Systems Biology Open Language (SBOL) data fetched from the SynBioHub design repository. The iBioSim software tool is then utilized to convert this SBOL description into a computational model encoded using the Systems Biology Markup Language (SBML). Finally, this SBML model can be simulated using a variety of methods. This workflow provides synthetic biologists with easy to use tools to create predictable biological systems, hiding away the complexity of building computational models. This approach can further be incorporated into other computational workflows for design automation.
Synthetic Biology Open Language Visual (SBOL Visual) Version 2.1
Abstract People who are engineering biological organisms often find it useful to communicate in diagrams, both about the structure of the nucleic acid sequences that they are engineering and about the functional relationships between sequence features and other molecular species . Some typical practices and conventions have begun to emerge for such diagrams. The Synthetic Biology Open Language Visual (SBOL Visual) has been developed as a standard for organizing and systematizing such conventions in order to produce a coherent language for expressing the structure and function of genetic designs. This document details version 2.1 of SBOL Visual, which builds on the prior SBOL Visual 2.0 standard by expanding diagram syntax to include methods for showing modular structure and mappings between elements of a system, interactions arrows that can split or join (with the glyph at the split or join indicating either superposition or a chemical process), and adding new glyphs for indicating genomic context (e.g., integration into a plasmid or genome) and for stop codons.
Synthetic Biology Open Language (SBOL) Version 2.3
textlesssection class="abstract"textgreatertextlessh2 class="abstractTitle text-title my-1" id="d230e2"textgreaterAbstracttextless/h2textgreatertextlessptextgreaterSynthetic biology builds upon the techniques and successes of genetics, molecular biology, and metabolic engineering by applying engineering principles to the design of biological systems. The field still faces substantial challenges, including long development times, high rates of failure, and poor reproducibility. One method to ameliorate these problems is to improve the exchange of information about designed systems between laboratories. The synthetic biology open language (SBOL) has been developed as a standard to support the specification and exchange of biological design information in synthetic biology, filling a need not satisfied by other pre-existing standards. This document details version 2.3.0 of SBOL, which builds upon version 2.2.0 published in last year’s JIB Standards in Systems Biology special issue. In particular, SBOL 2.3.0 includes means of succinctly representing sequence modifications, such as insertion, deletion, and replacement, an extension to support organization and attachment of experimental data derived from designs, and an extension for describing numerical parameters of design elements. The new version also includes specifying types of synthetic biology activities, unambiguous locations for sequences with multiple encodings, refinement of a number of validation rules, improved figures and examples, and clarification on a number of issues related to the use of external ontology terms.textless/ptextgreatertextless/sectiontextgreater
Synthetic Biology Open Language Visual (SBOL Visual) Version 2.1
People who are engineering biological organisms often find it useful to communicate in diagrams, both about the structure of the nucleic acid sequences that they are engineering and about the functional relationships between sequence features and other molecular species . Some typical practices and conventions have begun to emerge for such diagrams. The Synthetic Biology Open Language Visual (SBOL Visual) has been developed as a standard for organizing and systematizing such conventions in order to produce a coherent language for expressing the structure and function of genetic designs. This document details version 2.1 of SBOL Visual, which builds on the prior SBOL Visual 2.0 standard by expanding diagram syntax to include methods for showing modular structure and mappings between elements of a system, interactions arrows that can split or join (with the glyph at the split or join indicating either superposition or a chemical process), and adding new glyphs for indicating genomic context (e.g., integration into a plasmid or genome) and for stop codons.
Synthetic Biology Open Language (SBOL) Version 2.3
Synthetic biology builds upon the techniques and successes of genetics, molecular biology, and metabolic engineering by applying engineering principles to the design of biological systems. The field still faces substantial challenges, including long development times, high rates of failure, and poor reproducibility. One method to ameliorate these problems is to improve the exchange of information about designed systems between laboratories. The synthetic biology open language (SBOL) has been developed as a standard to support the specification and exchange of biological design information in synthetic biology, filling a need not satisfied by other pre-existing standards. This document details version 2.3.0 of SBOL, which builds upon version 2.2.0 published in last year’s JIB Standards in Systems Biology special issue. In particular, SBOL 2.3.0 includes means of succinctly representing sequence modifications, such as insertion, deletion, and replacement, an extension to support organization and attachment of experimental data derived from designs, and an extension for describing numerical parameters of design elements. The new version also includes specifying types of synthetic biology activities, unambiguous locations for sequences with multiple encodings, refinement of a number of validation rules, improved figures and examples, and clarification on a number of issues related to the use of external ontology terms.
DNA-based Communication in Populations of Synthetic Protocells
Developing molecular communication platforms based on orthogonal communication channels is a crucial step towards engineering artificial multicellular systems. Here, we present a general and scalable platform entitled ‘biomolecular implementation of protocellular communication’ (BIO-PC) to engineer distributed multichannel molecular communication between populations of non-lipid semipermeable microcapsules. Our method leverages the modularity and scalability of enzyme-free DNA strand-displacement circuits to develop protocellular consortia that can sense, process and respond to DNA-based messages. We engineer a rich variety of biochemical communication devices capable of cascaded amplification, bidirectional communication and distributed computational operations. Encapsulating DNA strand-displacement circuits further allows their use in concentrated serum where non-compartmentalized DNA circuits cannot operate. BIO-PC enables reliable execution of distributed DNA-based molecular programs in biologically relevant environments and opens new directions in DNA computing and minimal cell technology.
sboljs: Bringing the Synthetic Biology Open Language to the Web Browser
The Synthetic Biology Open Language (SBOL) is a data standard for the representation of engineered biological systems. SBOL is implemented in the form of software libraries which can be used to add SBOL support to both new and existing software tools. While existing libraries allow for software to be developed that runs on a server or is installed locally, they lack the capability to create SBOL software that runs directly in a Web browser. Here, we address this issue by presenting sboljs, a JavaScript software library for SBOL that is capable of being used both on the server and in the Web browser.
Sboljs: Bringing the Synthetic Biology Open Language to the Web Browser
The Synthetic Biology Open Language (SBOL) is a data standard for the representation of engineered biological systems. SBOL is implemented in the form of software libraries which can be used to add SBOL support to both new and existing software tools. While existing libraries allow for software to be developed that runs on a server or is installed locally, they lack the capability to create SBOL software that runs directly in a Web browser. Here, we address this issue by presenting sboljs, a JavaScript software library for SBOL that is capable of being used both on the server and in the Web browser.
SynBioHub: A Standards-Enabled Design Repository for Synthetic Biology
The SynBioHub repository (https://synbiohub.org) is an open-source software project that facilitates the sharing of information about engineered biological systems. SynBioHub provides computational access for software and data integration, and a graphical user interface that enables users to search for and share designs in a Web browser. By connecting to relevant repositories (e.g., the iGEM repository, JBEI ICE, and other instances of SynBioHub), the software allows users to browse, upload, and download data in various standard formats, regardless of their location or representation. SynBioHub also provides a central reference point for other resources to link to, delivering design information in a standardized format using the Synthetic Biology Open Language (SBOL). The adoption and use of SynBioHub, a community-driven effort, has the potential to overcome the reproducibility challenge across laboratories by helping to address the current lack of information about published designs.
SynBioHub: A Standards-Enabled Design Repository for Synthetic Biology
The SynBioHub repository (https://synbiohub.org) is an open-source software project that facilitates the sharing of information about engineered biological systems. SynBioHub provides computational access for software and data integration, and a graphical user interface that enables users to search for and share designs in a Web browser. By connecting to relevant repositories (e.g., the iGEM repository, JBEI ICE, and other instances of SynBioHub), the software allows users to browse, upload, and download data in various standard formats, regardless of their location or representation. SynBioHub also provides a central reference point for other resources to link to, delivering design information in a standardized format using the Synthetic Biology Open Language (SBOL). The adoption and use of SynBioHub, a community-driven effort, has the potential to overcome the reproducibility challenge across laboratories by helping to address the current lack of information about published designs.
Bio-Algorithmic Workflows for Standardized Synthetic Biology Constructs
A synthetic biology workflow covers the roadmap from conceptualization of a genetic device to its construction and measurement. It is composed of databases that provide DNA parts/plasmids, wet-lab methods , software tools to design circuits, simulation packages , and tools to analyze circuit performance. The interdisciplinary nature of such a workflow requires that experimental results and their in-silico counterparts proceed alongside, with constant feedback between them. We present an end-to-end use case for engineering a simple synthetic device, where information standards maintain coherence throughout the workflow. These are the Standard European Vector Architecture (SEVA), the Synthetic Biology Open Language (SBOL), and the Systems Biology Markup Language (SBML).
SBOLDesigner 2: An Intuitive Tool for Structural Genetic Design
As the Synthetic Biology Open Language (SBOL) data and visual standards gain acceptance for describing genetic designs in a detailed and reproducible way, there is an increasing need for an intuitive sequence editor tool that biologists can use that supports these standards. This paper describes SBOLDesigner 2, a genetic design automation (GDA) tool that natively supports both the SBOL data model (Version 2) and SBOL Visual (Version 1). This software is enabled to fetch and store parts and designs from SBOL repositories, such as SynBioHub. It can also import and export data about parts and designs in FASTA, GenBank, and SBOL 1 data format. Finally, it possesses a simple and intuitive user interface. This paper describes the design process using SBOLDesigner 2, highlighting new features over the earlier prototype versions. SBOLDesigner 2 is released freely and open source under the Apache 2.0 license.
A Visual Language for Protein Design
As protein engineering becomes more sophisticated, practitioners increasingly need to share diagrams for communicating protein designs. To this end, we present a draft visual language, Protein Language, that describes the high-level architecture of an engineered protein with easy-to-draw glyphs, intended to be compatible with other biological diagram languages such as SBOL Visual and SBGN. Protein Language consists of glyphs for representing important features (e.g., globular domains, recognition and localization sequences, sites of covalent modification, cleavage and catalysis), rules for composing these glyphs to represent complex architectures, and rules constraining the scaling and styling of diagrams. To support Protein Language we have implemented an extensible web-based software diagram tool, Protein Designer, that uses Protein Language in a “drag and drop” interface for visualization and computer-aided-design of engineered proteins, as well as conversion of annotated protein sequences to Protein Language diagrams and figure export. Protein Designer can be accessed at http://protlang.biocad.io/.
A Validator and Converter for the Synthetic Biology Open Language
This paper presents a new validation and conversion utility for the Synthetic Biology Open Language (SBOL). This utility can be accessed directly in software using the libSBOLj library, through a web interface, or using a web service via RESTful API calls. The validator checks all required and best practice rules set forth in the SBOL specification document, and it reports back to the user the location within the document of any errors found. The converter is capable of translating from/to SBOL 1, GenBank, and FASTA formats to/from SBOL 2. The SBOL Validator/Converter utility is released freely and open source under the Apache 2.0 license. The online version of the validator/converter utility can be found here: http://www.async.ece.utah.edu/sbol-validator/. The source code for the validator/converter can be found here: http://github.com/SynBioDex/SBOL-Validator/.
SBOLDesigner 2: An Intuitive Tool for Structural Genetic Design
As the Synthetic Biology Open Language (SBOL) data and visual standards gain acceptance for describing genetic designs in a detailed and reproducible way, there is an increasing need for an intuitive sequence editor tool that biologists can use that supports these standards. This paper describes SBOLDesigner 2, a genetic design automation (GDA) tool that natively supports both the SBOL data model (Version 2) and SBOL Visual (Version 1). This software is enabled to fetch and store parts and designs from SBOL repositories, such as SynBioHub. It can also import and export data about parts and designs in FASTA, GenBank, and SBOL 1 data format. Finally, it possesses a simple and intuitive user interface. This paper describes the design process using SBOLDesigner 2, highlighting new features over the earlier prototype versions. SBOLDesigner 2 is released freely and open source under the Apache 2.0 license.
A Visual Language for Protein Design
As protein engineering becomes more sophisticated, practitioners increasingly need to share diagrams for communicating protein designs. To this end, we present a draft visual language, Protein Language, that describes the high-level architecture of an engineered protein with easy-to-draw glyphs, intended to be compatible with other biological diagram languages such as SBOL Visual and SBGN. Protein Language consists of glyphs for representing important features (e.g., globular domains, recognition and localization sequences, sites of covalent modification, cleavage and catalysis), rules for composing these glyphs to represent complex architectures, and rules constraining the scaling and styling of diagrams. To support Protein Language we have implemented an extensible web-based software diagram tool, Protein Designer, that uses Protein Language in a ``drag and drop’’ interface for visualization and computer-aided-design of engineered proteins, as well as conversion of annotated protein sequences to Protein Language diagrams and figure export. Protein Designer can be accessed at http://biocad.ncl.ac.uk/protein-designer/.
A Validator and Converter for the Synthetic Biology Open Language
This paper presents a new validation and conversion utility for the Synthetic Biology Open Language (SBOL). This utility can be accessed directly in software using the libSBOLj library, through a web interface, or using a web service via RESTful API calls. The validator checks all required and best practice rules set forth in the SBOL specification document, and it reports back to the user the location within the document of any errors found. The converter is capable of translating from/to SBOL 1, GenBank, and FASTA formats to/from SBOL 2. The SBOL Validator/Converter utility is released freely and open source under the Apache 2.0 license. The online version of the validator/converter utility can be found here: http://www.async.ece.utah.edu/sbol-validator/. The source code for the validator/converter can be found here: http://github.com/SynBioDex/SBOL-Validator/.
A standard-enabled workflow for synthetic biology
A synthetic biology workflow is composed of data repositories that provide information about genetic parts, sequence-level design tools to compose these parts into circuits, visualization tools to depict these designs, genetic design tools to select parts to create systems, and modeling and simulation tools to evaluate alternative design choices. Data standards enable the ready exchange of information within such a workflow, allowing repositories and tools to be connected from a diversity of sources. The present paper describes one such workflow that utilizes, among others, the Synthetic Biology Open Language (SBOL) to describe genetic designs, the Systems Biology Markup Language to model these designs, and SBOL Visual to visualize these designs. We describe how a standard-enabled workflow can be used to produce types of design information, including multiple repositories and software tools exchanging information using a variety of data standards. Recently, the ACS Synthetic Biology journal has recommended the use of SBOL in their publications.
A Standard-Enabled Workflow for Synthetic Biology
A synthetic biology workflow is composed of data repositories that provide information about genetic parts, sequence-level design tools to compose these parts into circuits, visualization tools to depict these designs, genetic design tools to select parts to create systems, and modeling and simulation tools to evaluate alternative design choices. Data standards enable the ready exchange of information within such a workflow, allowing repositories and tools to be connected from a diversity of sources. The present paper describes one such workflow that utilizes, among others, the Synthetic Biology Open Language (SBOL) to describe genetic designs, the Systems Biology Markup Language to model these designs, and SBOL Visual to visualize these designs. We describe how a standard-enabled workflow can be used to produce types of design information, including multiple repositories and software tools exchanging information using a variety of data standards. Recently, the ACS Synthetic Biology journal has recommended the use of SBOL in their publications.
SBOLme: a Repository of SBOL Parts for Metabolic Engineering
The Synthetic Biology Open Language (SBOL) is a community-driven open language to promote standardization in synthetic biology. To support the use of SBOL in metabolic engineering, we developed SBOLme, the first open-access repository of SBOL 2-compliant biochemical parts for a wide range of metabolic engineering applications. The URL of our repository is https://web.archive.org/web/20201128054240/https://www.cbrc.kaust.edu.sa/sbolme/.
SBOLme: A Repository of SBOL Parts for Metabolic Engineering
The Synthetic Biology Open Language (SBOL) is a community-driven open language to promote standardization in synthetic biology. To support the use of SBOL in metabolic engineering, we developed SBOLme, the first open-access repository of SBOL 2-compliant biochemical parts for a wide range of metabolic engineering applications. The URL of our repository is http://www.cbrc.kaust.edu.sa/sbolme.
Data Integration and Mining for Synthetic Biology Design
One aim of synthetic biologists is to create novel and predictable biological systems from simpler modular parts. This approach is currently hampered by a lack of well-defined and characterized parts and devices. However, there is a wealth of existing biological information, which can be used to identify and characterize biological parts, and their design constraints in the literature and numerous biological databases. However, this information is spread among these databases in many different formats. New computational approaches are required to make this information available in an integrated format that is more amenable to data mining. A tried and tested approach to this problem is to map disparate data sources into a single data set, with common syntax and semantics, to produce a data warehouse or knowledge base. Ontologies have been used extensively in the life sciences, providing this common syntax and semantics as a model for a given biological domain, in a fashion that is amenable to computational analysis and reasoning. Here, we present an ontology for applications in synthetic biology design, SyBiOnt, which facilitates the modeling of information about biological parts and their relationships. SyBiOnt was used to create the SyBiOntKB knowledge base, incorporating and building upon existing life sciences ontologies and standards. The reasoning capabilities of ontologies were then applied to automate the mining of biological parts from this knowledge base. We propose that this approach will be useful to speed up synthetic biology design and ultimately help facilitate the automation of the biological engineering life cycle.
Data Integration and Mining for Synthetic Biology Design
One aim of synthetic biologists is to create novel and predictable biological systems from simpler modular parts. This approach is currently hampered by a lack of well-defined and characterized parts and devices. However, there is a wealth of existing biological information, which can be used to identify and characterize biological parts, and their design constraints in the literature and numerous biological databases. However, this information is spread among these databases in many different formats. New computational approaches are required to make this information available in an integrated format that is more amenable to data mining. A tried and tested approach to this problem is to map disparate data sources into a single data set, with common syntax and semantics, to produce a data warehouse or knowledge base. Ontologies have been used extensively in the life sciences, providing this common syntax and semantics as a model for a given biological domain, in a fashion that is amenable to computational analysis and reasoning. Here, we present an ontology for applications in synthetic biology design, SyBiOnt, which facilitates the modeling of information about biological parts and their relationships. SyBiOnt was used to create the SyBiOntKB knowledge base, incorporating and building upon existing life sciences ontologies and standards. The reasoning capabilities of ontologies were then applied to automate the mining of biological parts from this knowledge base. We propose that this approach will be useful to speed up synthetic biology design and ultimately help facilitate the automation of the biological engineering life cycle.
Synthetic Biology Open Language (SBOL) Version 2.1.0
Synthetic biology builds upon the techniques and successes of genetics, molecular biology, and metabolic engineering by applying engineering principles to the design of biological systems. The field still faces substantial challenges, including long development times, high rates of failure, and poor reproducibility. One method to ameliorate these problems would be to improve the exchange of information about designed systems between laboratories. The Synthetic Biology Open Language (SBOL) has been developed as a standard to support the specification and exchange of biological design information in synthetic biology, filling a need not satisfied by other pre-existing standards. This document details version 2.1 of SBOL that builds upon version 2.0 published in last year’s JIB special issue. In particular, SBOL 2.1 includes improved rules for what constitutes a valid SBOL document, new role fields to simplify the expression of sequence features and how components are used in context, and new best practices descriptions to improve the exchange of basic sequence topology information and the description of genetic design provenance, as well as miscellaneous other minor improvements.
Synthetic Biology Open Language (SBOL) Version 2.1.0
textlesssection class="abstract"textgreatertextlessh2 class="abstractTitle text-title my-1" id="d807e2"textgreaterSummarytextless/h2textgreatertextlessptextgreaterSynthetic biology builds upon the techniques and successes of genetics, molecular biology, and metabolic engineering by applying engineering principles to the design of biological systems. The field still faces substantial challenges, including long development times, high rates of failure, and poor reproducibility. One method to ameliorate these problems would be to improve the exchange of information about designed systems between laboratories. The Synthetic Biology Open Language (SBOL) has been developed as a standard to support the specification and exchange of biological design information in synthetic biology, filling a need not satisfied by other pre-existing standards. This document details version 2.1 of SBOL that builds upon version 2.0 published in last year’s JIB special issue. In particular, SBOL 2.1 includes improved rules for what constitutes a valid SBOL document, new role fields to simplify the expression of sequence features and how components are used in context, and new best practices descriptions to improve the exchange of basic sequence topology information and the description of genetic design provenance, as well as miscellaneous other minor improvements.textless/ptextgreatertextless/sectiontextgreater
VisBOL: Web-Based Tools for Synthetic Biology Design Visualization
VisBOL is a Web-based application that allows the rendering of genetic circuit designs, enabling synthetic biologists to visually convey designs in SBOL visual format. VisBOL designs can be exported to formats including PNG and SVG images to be embedded in Web pages, presentations and publications. The VisBOL tool enables the automated generation of visualizations from designs specified using the Synthetic Biology Open Language (SBOL) version 2.0, as well as a range of well-known bioinformatics formats including GenBank and Pigeoncad notation. VisBOL is provided both as a user accessible Web site and as an open-source (BSD) JavaScript library that can be used to embed diagrams within other content and software.
VisBOL: Web-Based Tools for Synthetic Biology Design Visualization
VisBOL is a Web-based application that allows the rendering of genetic circuit designs, enabling synthetic biologists to visually convey designs in SBOL visual format. VisBOL designs can be exported to formats including PNG and SVG images to be embedded in Web pages, presentations and publications. The VisBOL tool enables the automated generation of visualizations from designs specified using the Synthetic Biology Open Language (SBOL) version 2.0, as well as a range of well-known bioinformatics formats including GenBank and Pigeoncad notation. VisBOL is provided both as a user accessible Web site and as an open-source (BSD) JavaScript library that can be used to embed diagrams within other content and software.
The SBOL Stack: A Platform for Storing, Publishing, and Sharing Synthetic Biology Designs
Recently, synthetic biologists have developed the Synthetic Biology Open Language (SBOL), a data exchange standard for descriptions of genetic parts, devices, modules, and systems. The goals of this standard are to allow scientists to exchange designs of biological parts and systems, to facilitate the storage of genetic designs in repositories, and to facilitate the description of genetic designs in publications. In order to achieve these goals, the development of an infrastructure to store, retrieve, and exchange SBOL data is necessary. To address this problem, we have developed the SBOL Stack, a Resource Description Framework (RDF) database specifically designed for the storage, integration, and publication of SBOL data. This database allows users to define a library of synthetic parts and designs as a service, to share SBOL data with collaborators, and to store designs of biological systems locally. The database also allows external data sources to be integrated by mapping them to the SBOL data model. The SBOL Stack includes two Web interfaces: the SBOL Stack API and SynBioHub. While the former is designed for developers, the latter allows users to upload new SBOL biological designs, download SBOL documents, search by keyword, and visualize SBOL data. Since the SBOL Stack is based on semantic Web technology, the inherent distributed querying functionality of RDF databases can be used to allow different SBOL stack databases to be queried simultaneously, and therefore, data can be shared between different institutes, centers, or other users.
Sharing Structure and Function in Biological Design with SBOL 2.0
The Synthetic Biology Open Language (SBOL) is a standard that enables collaborative engineering of biological systems across different institutions and tools. SBOL is developed through careful consideration of recent synthetic biology trends, real use cases, and consensus among leading researchers in the field and members of commercial biotechnology enterprises. We demonstrate and discuss how a set of SBOL-enabled software tools can form an integrated, cross-organizational workflow to recapitulate the design of one of the largest published genetic circuits to date, a 4-input AND sensor. This design encompasses the structural components of the system, such as its DNA, RNA, small molecules, and proteins, as well as the interactions between these components that determine the system’s behavior/function. The demonstrated workflow and resulting circuit design illustrate the utility of SBOL 2.0 in automating the exchange of structural and functional specifications for genetic parts, devices, and the biological systems in which they operate.
Improving Synthetic Biology Communication: Recommended Practices for Visual Depiction and Digital Submission of Genetic Designs
Research is communicated more effectively and reproducibly when articles depict genetic designs consistently and fully disclose the complete sequences of all reported constructs. ACS Synthetic Biology is now providing authors with updated guidance and piloting a new tool and publication workflow that facilitate compliance with these recommended practices and standards for visual representation and data exchange.
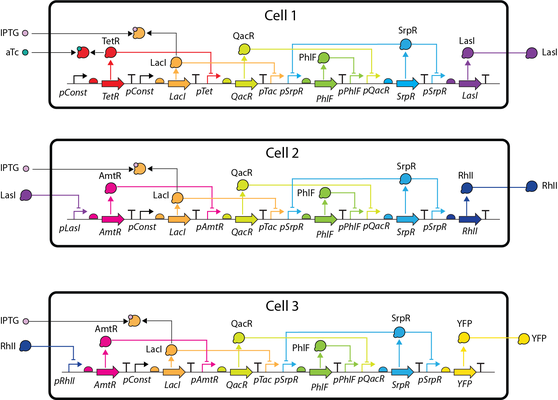
A Converter from the Systems Biology Markup Language to the Synthetic Biology Open Language
Standards are important to synthetic biology because they enable exchange and reproducibility of genetic designs. This paper describes a procedure for converting between two standards: the Systems Biology Markup Language (SBML) and the Synthetic Biology Open Language (SBOL). SBML is a standard for behavioral models of biological systems at the molecular level. SBOL describes structural and basic qualitative behavioral aspects of a biological design. Converting SBML to SBOL enables a consistent connection between behavioral and structural information for a biological design. The conversion process described in this paper leverages Systems Biology Ontology (SBO) annotations to enable inference of a designs qualitative function.
The SBOL Stack: A Platform for Storing, Publishing, and Sharing Synthetic Biology Designs
Recently, synthetic biologists have developed the Synthetic Biology Open Language (SBOL), a data exchange standard for descriptions of genetic parts, devices, modules, and systems. The goals of this standard are to allow scientists to exchange designs of biological parts and systems, to facilitate the storage of genetic designs in repositories, and to facilitate the description of genetic designs in publications. In order to achieve these goals, the development of an infrastructure to store, retrieve, and exchange SBOL data is necessary. To address this problem, we have developed the SBOL Stack, a Resource Description Framework (RDF) database specifically designed for the storage, integration, and publication of SBOL data. This database allows users to define a library of synthetic parts and designs as a service, to share SBOL data with collaborators, and to store designs of biological systems locally. The database also allows external data sources to be integrated by mapping them to the SBOL data model. The SBOL Stack includes two Web interfaces: the SBOL Stack API and SynBioHub. While the former is designed for developers, the latter allows users to upload new SBOL biological designs, download SBOL documents, search by keyword, and visualize SBOL data. Since the SBOL Stack is based on semantic Web technology, the inherent distributed querying functionality of RDF databases can be used to allow different SBOL stack databases to be queried simultaneously, and therefore, data can be shared between different institutes, centers, or other users.
Sharing Structure and Function in Biological Design with SBOL 2.0
The Synthetic Biology Open Language (SBOL) is a standard that enables collaborative engineering of biological systems across different institutions and tools. SBOL is developed through careful consideration of recent synthetic biology trends, real use cases, and consensus among leading researchers in the field and members of commercial biotechnology enterprises. We demonstrate and discuss how a set of SBOL-enabled software tools can form an integrated, cross-organizational workflow to recapitulate the design of one of the largest published genetic circuits to date, a 4-input AND sensor. This design encompasses the structural components of the system, such as its DNA, RNA, small molecules, and proteins, as well as the interactions between these components that determine the system’s behavior/function. The demonstrated workflow and resulting circuit design illustrate the utility of SBOL 2.0 in automating the exchange of structural and functional specifications for genetic parts, devices, and the biological systems in which they operate.
Improving Synthetic Biology Communication: Recommended Practices for Visual Depiction and Digital Submission of Genetic Designs
Research is communicated more effectively and reproducibly when articles depict genetic designs consistently and fully disclose the complete sequences of all reported constructs. ACS Synthetic Biology is now providing authors with updated guidance and piloting a new tool and publication workflow that facilitate compliance with these recommended practices and standards for visual representation and data exchange.
A Converter from the Systems Biology Markup Language to the Synthetic Biology Open Language
Standards are important to synthetic biology because they enable exchange and reproducibility of genetic designs. This paper describes a procedure for converting between two standards: the Systems Biology Markup Language (SBML) and the Synthetic Biology Open Language (SBOL). SBML is a standard for behavioral models of biological systems at the molecular level. SBOL describes structural and basic qualitative behavioral aspects of a biological design. Converting SBML to SBOL enables a consistent connection between behavioral and structural information for a biological design. The conversion process described in this paper leverages Systems Biology Ontology (SBO) annotations to enable inference of a designs qualitative function.
SBOL Visual: A Graphical Language for Genetic Designs
Synthetic Biology Open Language (SBOL) Visual is a graphical standard for genetic engineering. It consists of symbols representing DNA subsequences, including regulatory elements and DNA assembly features. These symbols can be used to draw illustrations for communication and instruction, and as image assets for computer-aided design. SBOL Visual is a community standard, freely available for personal, academic, and commercial use (Creative Commons CC0 license). We provide prototypical symbol images that have been used in scientific publications and software tools. We encourage users to use and modify them freely, and to join the SBOL Visual community: http://www.sbolstandard.org/visual-about.
SBOL Visual: A Graphical Language for Genetic Designs
Synthetic Biology Open Language (SBOL) Visual is a graphical standard for genetic engineering. It consists of symbols representing DNA subsequences, including regulatory elements and DNA assembly features. These symbols can be used to draw illustrations for communication and instruction, and as image assets for computer-aided design. SBOL Visual is a community standard, freely available for personal, academic, and commercial use (Creative Commons CC0 license). We provide prototypical symbol images that have been used in scientific publications and software tools. We encourage users to use and modify them freely, and to join the SBOL Visual community: http://www.sbolstandard.org/visual.
libSBOLj 2.0: A Java Library to Support SBOL 2.0
The Synthetic Biology Open Language (SBOL) is an emerging data standard for representing synthetic biology designs. The goal of SBOL is to improve the reproducibility of these designs and their electronic exchange between researchers and/or genetic design automation tools. The latest version of the standard, SBOL 2.0, enables the annotation of a large variety of biological components (e.g., DNA, RNA, proteins, complexes, small molecules, etc.) and their interactions. SBOL 2.0 also allows researchers to organize components into hierarchical modules, to specify their intended functions, and to link modules to models that describe their behavior mathematically. To support the use of SBOL 2.0, we have developed the libSBOLj 2.0 Java library, which provides an easy to use Application Programming Interface (API) for developers, including manipulation of SBOL constructs, serialization to and from an RDF/XML file format, and migration support in the form of conversion from the prior SBOL 1.1 standard to SBOL 2.0. This letter describes the libSBOLj 2.0 library and key engineering decisions involved in its design.

Composable Modular Models for Synthetic Biology
Modelling and computational simulation are crucial for the large-scale engineering of biological circuits since they allow the system under design to be simulated prior to implementation in vivo. To support automated, model-driven design it is desirable that in silico models are modular, composable and use standard formats. The synthetic biology design process typically involves the composition of genetic circuits from individual parts. At the most basic level, these parts are representations of genetic features such as promoters, ribosome binding sites (RBSs), and coding sequences (CDSs). However, it is also desirable to model the biological molecules and behaviour that arise when these parts are combined in vivo. Modular models of parts can be composed and their associated systems simulated, facilitating the process of model-centred design. The availability of databases of modular models is essential to support software tools used in the model-driven design process. In this article, we present an approach to support the development of composable, modular models for synthetic biology, termed Standard Virtual Parts. We then describe a programmatically accessible and publicly available database of these models to allow their use by computational design tools.
Generating Systems Biology Markup Language Models from the Synthetic Biology Open Language
In the context of synthetic biology, model generation is the automated process of constructing biochemical models based on genetic designs. This paper discusses the use cases for model generation in genetic design automation (GDA) software tools and introduces the foundational concepts of standards and model annotation that make this process useful. Finally, this paper presents an implementation of model generation in the GDA software tool iBioSim and provides an example of generating a Systems Biology Markup Language (SBML) model from a design of a 4-input AND sensor written in the Synthetic Biology Open Language (SBOL).
Generating Systems Biology Markup Language Models from the Synthetic Biology Open Language
In the context of synthetic biology, model generation is the automated process of constructing biochemical models based on genetic designs. This paper discusses the use cases for model generation in genetic design automation (GDA) software tools and introduces the foundational concepts of standards and model annotation that make this process useful. Finally, this paper presents an implementation of model generation in the GDA software tool iBioSim and provides an example of generating a Systems Biology Markup Language (SBML) model from a design of a 4-input AND sensor written in the Synthetic Biology Open Language (SBOL).
The Synthetic Biology Open Language
The design and construction of engineered organisms is an emerging new discipline called synthetic biology and holds considerable promise as a new technological platform. The design of biologically engineered systems is however nontrivial, requiring contributions from a wide array of disciplines. One particular issue that confronts synthetic biologists is the ability to unambiguously describe novel designs such that they can be reengineered by a third-party. For this reason, the synthetic biology open language (SBOL) was developed as a community wide standard for formally representing biological designs. A design created by one engineering team can be transmitted electronically to another who can then use this design to reproduce the experimental results. The development and the community of the SBOL standard started in 2008 and has since grown in use with now over 80 participants, including international, academic, and industrial interests. SBOL has stimulated the development of repositories and software tools to help synthetic biologists in their design efforts. This chapter summarizes the latest developments and future of the SBOL standard and its supporting infrastructure.
The Synthetic Biology Open Language
The design and construction of engineered organisms is an emerging new discipline called synthetic biology and holds considerable promise as a new technological platform. The design of biologically engineered systems is however nontrivial, requiring contributions from a wide array of disciplines. One particular issue that confronts synthetic biologists is the ability to unambiguously describe novel designs such that they can be reengineered by a third-party. For this reason, the synthetic biology open language (SBOL) was developed as a community wide standard for formally representing biological designs. A design created by one engineering team can be transmitted electronically to another who can then use this design to reproduce the experimental results. The development and the community of the SBOL standard started in 2008 and has since grown in use with now over 80 participants, including international, academic, and industrial interests. SBOL has stimulated the development of repositories and software tools to help synthetic biologists in their design efforts. This chapter summarizes the latest developments and future of the SBOL standard and its supporting infrastructure.
Directed Acyclic Graph-Based Technology Mapping of Genetic Circuit Models
As engineering foundations such as standards and abstraction begin to mature within synthetic biology, it is vital that genetic design automation (GDA) tools be developed to enable synthetic biologists to automatically select standardized DNA components from a library to meet the behavioral specification for a genetic circuit. To this end, we have developed a genetic technology mapping algorithm that builds on the directed acyclic graph (DAG) based mapping techniques originally used to select parts for digital electronic circuit designs and implemented it in our GDA tool, iBioSim. It is among the first genetic technology mapping algorithms to adapt techniques from electronic circuit design, in particular the use of a cost function to guide the search for an optimal solution, and perhaps that which makes the greatest use of standards for describing genetic function and structure to represent design specifications and component libraries. This paper demonstrates the use of our algorithm to map the specifications for three different genetic circuits against four randomly generated libraries of increasing size to evaluate its performance against both exhaustive search and greedy variants for finding optimal and near-optimal solutions.
Directed Acyclic Graph-Based Technology Mapping of Genetic Circuit Models
As engineering foundations such as standards and abstraction begin to mature within synthetic biology, it is vital that genetic design automation (GDA) tools be developed to enable synthetic biologists to automatically select standardized DNA components from a library to meet the behavioral specification for a genetic circuit. To this end, we have developed a genetic technology mapping algorithm that builds on the directed acyclic graph (DAG) based mapping techniques originally used to select parts for digital electronic circuit designs and implemented it in our GDA tool, iBioSim. It is among the first genetic technology mapping algorithms to adapt techniques from electronic circuit design, in particular the use of a cost function to guide the search for an optimal solution, and perhaps that which makes the greatest use of standards for describing genetic function and structure to represent design specifications and component libraries. This paper demonstrates the use of our algorithm to map the specifications for three different genetic circuits against four randomly generated libraries of increasing size to evaluate its performance against both exhaustive search and greedy variants for finding optimal and near-optimal solutions.
A Brief History of Synthetic Biology
In this Timeline article, Collins and colleagues chart the history of synthetic biology since its inception just over a decade ago, with a focus on both the cultural and scientific progress that has been made as well as on key breakthroughs and areas for future development.
A brief history of synthetic biology
In this Timeline article, Collins and colleagues chart the history of synthetic biology since its inception just over a decade ago, with a focus on both the cultural and scientific progress that has been made as well as on key breakthroughs and areas for future development.
A Methodology to Annotate Systems Biology Markup Language Models with the Synthetic Biology Open Language
Recently, we have begun to witness the potential of synthetic biology, noted here in the form of bacteria and yeast that have been genetically engineered to produce biofuels, manufacture drug precursors, and even invade tumor cells. The success of these projects, however, has often failed in translation and application to new projects, a problem exacerbated by a lack of engineering standards that combine descriptions of the structure and function of DNA. To address this need, this paper describes a methodology to connect the systems biology markup language (SBML) to the synthetic biology open language (SBOL), existing standards that describe biochemical models and DNA components, respectively. Our methodology involves first annotating SBML model elements such as species and reactions with SBOL DNA components. A graph is then constructed from the model, with vertices corresponding to elements within the model and edges corresponding to the cause-and-effect relationships between these elements. Lastly, the graph is traversed to assemble the annotating DNA components into a composite DNA component, which is used to annotate the model itself and can be referenced by other composite models and DNA components. In this way, our methodology can be used to build up a hierarchical library of models annotated with DNA components. Such a library is a useful input to any future genetic technology mapping algorithm that would automate the process of composing DNA components to satisfy a behavioral specification. Our methodology for SBML-to-SBOL annotation is implemented in the latest version of our genetic design automation (GDA) software tool, iBioSim.
A Methodology to Annotate Systems Biology Markup Language Models with the Synthetic Biology Open Language
Recently, we have begun to witness the potential of synthetic biology, noted here in the form of bacteria and yeast that have been genetically engineered to produce biofuels, manufacture drug precursors, and even invade tumor cells. The success of these projects, however, has often failed in translation and application to new projects, a problem exacerbated by a lack of engineering standards that combine descriptions of the structure and function of DNA. To address this need, this paper describes a methodology to connect the systems biology markup language (SBML) to the synthetic biology open language (SBOL), existing standards that describe biochemical models and DNA components, respectively. Our methodology involves first annotating SBML model elements such as species and reactions with SBOL DNA components. A graph is then constructed from the model, with vertices corresponding to elements within the model and edges corresponding to the cause-and-effect relationships between these elements. Lastly, the graph is traversed to assemble the annotating DNA components into a composite DNA component, which is used to annotate the model itself and can be referenced by other composite models and DNA components. In this way, our methodology can be used to build up a hierarchical library of models annotated with DNA components. Such a library is a useful input to any future genetic technology mapping algorithm that would automate the process of composing DNA components to satisfy a behavioral specification. Our methodology for SBML-to-SBOL annotation is implemented in the latest version of our genetic design automation (GDA) software tool, iBioSim.
Pigeon: A Design Visualizer for Synthetic Biology
Pigeon is a Web-based tool that translates a textual description of a synthetic biology design into an image. It allows programmatic generation of design visualizations, is easy to learn, is easily extensible to new glyphs and notation, and can be connected to other software tools for visualizing their output. We present the Pigeon syntax, its current command set, and some examples of Pigeon programs and their output.
Pigeon: A Design Visualizer for Synthetic Biology
Pigeon is a Web-based tool that translates a textual description of a synthetic biology design into an image. It allows programmatic generation of design visualizations, is easy to learn, is easily extensible to new glyphs and notation, and can be connected to other software tools for visualizing their output. We present the Pigeon syntax, its current command set, and some examples of Pigeon programs and their output.
Dynamic Modeling of Cellular Populations within iBioSim
As the complexity of synthetic genetic circuits increases, modeling is becoming a necessary first step to inform subsequent experimental efforts. In recent years, the design automation community has developed a wealth of computational tools for assisting experimentalists in designing and analyzing new genetic circuits at several scales. However, existing software primarily caters to either the DNA- or single-cell level, with little support for the multicellular level. To address this need, the iBioSim software package has been enhanced to provide support for modeling, simulating, and visualizing dynamic cellular populations in a two-dimensional space. This capacity is fully integrated into the software, capitalizing on iBioSim’s strengths in modeling, simulating, and analyzing single-celled systems.
Dynamic Modeling of Cellular Populations within iBioSim
As the complexity of synthetic genetic circuits increases, modeling is becoming a necessary first step to inform subsequent experimental efforts. In recent years, the design automation community has developed a wealth of computational tools for assisting experimentalists in designing and analyzing new genetic circuits at several scales. However, existing software primarily caters to either the DNA- or single-cell level, with little support for the multicellular level. To address this need, the iBioSim software package has been enhanced to provide support for modeling, simulating, and visualizing dynamic cellular populations in a two-dimensional space. This capacity is fully integrated into the software, capitalizing on iBioSim’s strengths in modeling, simulating, and analyzing single-celled systems.
DeviceEditor Visual Biological CAD Canvas
Biological Computer Aided Design (bioCAD) assists the de novo design and selection of existing genetic components to achieve a desired biological activity, as part of an integrated design-build-test cycle. To meet the emerging needs of Synthetic Biology, bioCAD tools must address the increasing prevalence of combinatorial library design, design rule specification, and scar-less multi-part DNA assembly.
DeviceEditor visual biological CAD canvas
Biological Computer Aided Design (bioCAD) assists the de novo design and selection of existing genetic components to achieve a desired biological activity, as part of an integrated design-build-test cycle. To meet the emerging needs of Synthetic Biology, bioCAD tools must address the increasing prevalence of combinatorial library design, design rule specification, and scar-less multi-part DNA assembly.
Synthetic Biology Open Language (SBOL) Version 1.1.0
In this BioBricks Foundation Request for Comments (BBF RFC), we specify the Synthetic Biology Open Language (SBOL) Version 1.1.0 to enable the electronic exchange of information describing DNA components used in synthetic biology. We define: 1. the vocabulary, a set of preferred terms and 2. the core data model, a common computational representation.
Synthetic Biology Open Language (SBOL) Version 1.1.0
In this BioBricks Foundation Request for Comments (BBF RFC), we specify the Synthetic Biology Open Language (SBOL) Version 1.1.0 to enable the electronic exchange of information describing DNA components used in synthetic biology. We define: 1. the vocabulary, a set of preferred terms and 2. the core data model, a common computational representation.
Automated Selection of Synthetic Biology Parts for Genetic Regulatory Networks
Raising the level of abstraction for synthetic biology design requires solving several challenging problems, including mapping abstract designs to DNA sequences. In this paper we present the first formalism and algorithms to address this problem. The key steps of this transformation are feature matching, signal matching, and part matching. Feature matching ensures that the mapping satisfies the regulatory relationships in the abstract design. Signal matching ensures that the expression levels of functional units are compatible. Finally, part matching finds a DNA part sequence that can implement the design. Our software tool MatchMaker implements these three steps.
An End-to-End Workflow for Engineering of Biological Networks from High-Level Specifications
We present a workflow for the design and production of biological networks from high-level program specifications. The workflow is based on a sequence of intermediate models that incrementally translate high-level specifications into DNA samples that implement them. We identify algorithms for translating between adjacent models and implement them as a set of software tools, organized into a four-stage toolchain: Specification, Compilation, Part Assignment, and Assembly. The specification stage begins with a Boolean logic computation specified in the Proto programming language. The compilation stage uses a library of network motifs and cellular platforms, also specified in Proto, to transform the program into an optimized Abstract Genetic Regulatory Network (AGRN) that implements the programmed behavior. The part assignment stage assigns DNA parts to the AGRN, drawing the parts from a database for the target cellular platform, to create a DNA sequence implementing the AGRN. Finally, the assembly stage computes an optimized assembly plan to create the DNA sequence from available part samples, yielding a protocol for producing a sample of engineered plasmids with robotics assistance. Our workflow is the first to automate the production of biological networks from a high-level program specification. Furthermore, the workflow’s modular design allows the same program to be realized on different cellular platforms simply by swapping workflow configurations. We validated our workflow by specifying a small-molecule sensor-reporter program and verifying the resulting plasmids in both HEK 293 mammalian cells and in E. coli bacterial cells.
Automated Selection of Synthetic Biology Parts for Genetic Regulatory Networks
Raising the level of abstraction for synthetic biology design requires solving several challenging problems, including mapping abstract designs to DNA sequences. In this paper we present the first formalism and algorithms to address this problem. The key steps of this transformation are feature matching, signal matching, and part matching. Feature matching ensures that the mapping satisfies the regulatory relationships in the abstract design. Signal matching ensures that the expression levels of functional units are compatible. Finally, part matching finds a DNA part sequence that can implement the design. Our software tool MatchMaker implements these three steps.
An End-to-End Workflow for Engineering of Biological Networks from High-Level Specifications
We present a workflow for the design and production of biological networks from high-level program specifications. The workflow is based on a sequence of intermediate models that incrementally translate high-level specifications into DNA samples that implement them. We identify algorithms for translating between adjacent models and implement them as a set of software tools, organized into a four-stage toolchain: Specification, Compilation, Part Assignment, and Assembly. The specification stage begins with a Boolean logic computation specified in the Proto programming language. The compilation stage uses a library of network motifs and cellular platforms, also specified in Proto, to transform the program into an optimized Abstract Genetic Regulatory Network (AGRN) that implements the programmed behavior. The part assignment stage assigns DNA parts to the AGRN, drawing the parts from a database for the target cellular platform, to create a DNA sequence implementing the AGRN. Finally, the assembly stage computes an optimized assembly plan to create the DNA sequence from available part samples, yielding a protocol for producing a sample of engineered plasmids with robotics assistance. Our workflow is the first to automate the production of biological networks from a high-level program specification. Furthermore, the workflow’s modular design allows the same program to be realized on different cellular platforms simply by swapping workflow configurations. We validated our workflow by specifying a small-molecule sensor-reporter program and verifying the resulting plasmids in both HEK 293 mammalian cells and in E. coli bacterial cells.
Design and Test of Genetic Circuits Using $tt iBioSim$iBioSim
The simulation of biological systems prior to their physical implementation can save time, money, and potentially provide insights into alternate designs. This paper presents a simulation environment which allows for a visual design process ultimately leading to a formal model which can be efficiently simulated.
Design and Test of Genetic Circuits Using $ tt iBioSim$iBioSim
The simulation of biological systems prior to their physical implementation can save time, money, and potentially provide insights into alternate designs. This paper presents a simulation environment which allows for a visual design process ultimately leading to a formal model which can be efficiently simulated.
Refactoring the Nitrogen Fixation Gene Cluster from Klebsiella Oxytoca
Bacterial genes associated with a single trait are often grouped in a contiguous unit of the genome known as a gene cluster. It is difficult to genetically manipulate many gene clusters because of complex, redundant, and integrated host regulation. We have developed a systematic approach to completely specify the genetics of a gene cluster by rebuilding it from the bottom up using only synthetic, well-characterized parts. This process removes all native regulation, including that which is undiscovered. First, all noncoding DNA, regulatory proteins, and nonessential genes are removed. The codons of essential genes are changed to create a DNA sequence as divergent as possible from the wild-type (WT) gene. Recoded genes are computationally scanned to eliminate internal regulation. They are organized into operons and placed under the control of synthetic parts (promoters, ribosome binding sites, and terminators) that are functionally separated by spacer parts. Finally, a controller consisting of genetic sensors and circuits regulates the conditions and dynamics of gene expression. We applied this approach to an agriculturally relevant gene cluster from Klebsiella oxytoca encoding the nitrogen fixation pathway for converting atmospheric N2 to ammonia. The native gene cluster consists of 20 genes in seven operons and is encoded in 23.5 kb of DNA. We constructed a ``refactored’’ gene cluster that shares little DNA sequence identity with WT and for which the function of every genetic part is defined. This work demonstrates the potential for synthetic biology tools to rewrite the genetics encoding complex biological functions to facilitate access, engineering, and transferability.
Refactoring the nitrogen fixation gene cluster from Klebsiella oxytoca
Bacterial genes associated with a single trait are often grouped in a contiguous unit of the genome known as a gene cluster. It is difficult to genetically manipulate many gene clusters because of complex, redundant, and integrated host regulation. We have developed a systematic approach to completely specify the genetics of a gene cluster by rebuilding it from the bottom up using only synthetic, well-characterized parts. This process removes all native regulation, including that which is undiscovered. First, all noncoding DNA, regulatory proteins, and nonessential genes are removed. The codons of essential genes are changed to create a DNA sequence as divergent as possible from the wild-type (WT) gene. Recoded genes are computationally scanned to eliminate internal regulation. They are organized into operons and placed under the control of synthetic parts (promoters, ribosome binding sites, and terminators) that are functionally separated by spacer parts. Finally, a controller consisting of genetic sensors and circuits regulates the conditions and dynamics of gene expression. We applied this approach to an agriculturally relevant gene cluster from Klebsiella oxytoca encoding the nitrogen fixation pathway for converting atmospheric N2 to ammonia. The native gene cluster consists of 20 genes in seven operons and is encoded in 23.5 kb of DNA. We constructed a “refactored” gene cluster that shares little DNA sequence identity with WT and for which the function of every genetic part is defined. This work demonstrates the potential for synthetic biology tools to rewrite the genetics encoding complex biological functions to facilitate access, engineering, and transferability.
Title: Synthetic Biology Open Language (SBOL) Version 1.0.0
In this BioBricks Foundation Request for Comments (BBF RFC), we specify the Synthetic Biology Open Language (SBOL) Version 1.0.0 to enable the electronic exchange of information describing DNA components used in synthetic biology. We define: 1. the vocabulary, a set of preferred terms and 2. the core data model, a common computational representation.
Title: Synthetic Biology Open Language (SBOL) Version 1.0.0
In this BioBricks Foundation Request for Comments (BBF RFC), we specify the Synthetic Biology Open Language (SBOL) Version 1.0.0 to enable the electronic exchange of information describing DNA components used in synthetic biology. We define: 1. the vocabulary, a set of preferred terms and 2. the core data model, a common computational representation.
Eugene – A Domain Specific Language for Specifying and Constraining Synthetic Biological Parts, Devices, and Systems
Background Synthetic biological systems are currently created by an ad-hoc, iterative process of specification, design, and assembly. These systems would greatly benefit from a more formalized and rigorous specification of the desired system components as well as constraints on their composition. Therefore, the creation of robust and efficient design flows and tools is imperative. We present a human readable language (Eugene) that allows for the specification of synthetic biological designs based on biological parts, as well as provides a very expressive constraint system to drive the automatic creation of composite Parts (Devices) from a collection of individual Parts. Results We illustrate Eugene’s capabilities in three different areas: Device specification, design space exploration, and assembly and simulation integration. These results highlight Eugene’s ability to create combinatorial design spaces and prune these spaces for simulation or physical assembly. Eugene creates functional designs quickly and cost-effectively. Conclusions Eugene is intended for forward engineering of DNA-based devices, and through its data types and execution semantics, reflects the desired abstraction hierarchy in synthetic biology. Eugene provides a powerful constraint system which can be used to drive the creation of new devices at runtime. It accomplishes all of this while being part of a larger tool chain which includes support for design, simulation, and physical device assembly.
Eugene – A Domain Specific Language for Specifying and Constraining Synthetic Biological Parts, Devices, and Systems
Background Synthetic biological systems are currently created by an ad-hoc, iterative process of specification, design, and assembly. These systems would greatly benefit from a more formalized and rigorous specification of the desired system components as well as constraints on their composition. Therefore, the creation of robust and efficient design flows and tools is imperative. We present a human readable language (Eugene) that allows for the specification of synthetic biological designs based on biological parts, as well as provides a very expressive constraint system to drive the automatic creation of composite Parts (Devices) from a collection of individual Parts. Results We illustrate Eugene’s capabilities in three different areas: Device specification, design space exploration, and assembly and simulation integration. These results highlight Eugene’s ability to create combinatorial design spaces and prune these spaces for simulation or physical assembly. Eugene creates functional designs quickly and cost-effectively. Conclusions Eugene is intended for forward engineering of DNA-based devices, and through its data types and execution semantics, reflects the desired abstraction hierarchy in synthetic biology. Eugene provides a powerful constraint system which can be used to drive the creation of new devices at runtime. It accomplishes all of this while being part of a larger tool chain which includes support for design, simulation, and physical device assembly.
Standard Biological Parts Knowledgebase
We have created the Knowledgebase of Standard Biological Parts (SBPkb) as a publically accessible Semantic Web resource for synthetic biology (sbolstandard.org). The SBPkb allows researchers to query and retrieve standard biological parts for research and use in synthetic biology. Its initial version includes all of the information about parts stored in the Registry of Standard Biological Parts (partsregistry.org). SBPkb transforms this information so that it is computable, using our semantic framework for synthetic biology parts. This framework, known as SBOL-semantic, was built as part of the Synthetic Biology Open Language (SBOL), a project of the Synthetic Biology Data Exchange Group. SBOL-semantic represents commonly used synthetic biology entities, and its purpose is to improve the distribution and exchange of descriptions of biological parts. In this paper, we describe the data, our methods for transformation to SBPkb, and finally, we demonstrate the value of our knowledgebase with a set of sample queries. We use RDF technology and SPARQL queries to retrieve candidate “promoter” parts that are known to be both negatively and positively regulated. This method provides new web based data access to perform searches for parts that are not currently possible.
Standard Biological Parts Knowledgebase
We have created the Knowledgebase of Standard Biological Parts (SBPkb) as a publically accessible Semantic Web resource for synthetic biology (sbolstandard.org). The SBPkb allows researchers to query and retrieve standard biological parts for research and use in synthetic biology. Its initial version includes all of the information about parts stored in the Registry of Standard Biological Parts (partsregistry.org). SBPkb transforms this information so that it is computable, using our semantic framework for synthetic biology parts. This framework, known as SBOL-semantic, was built as part of the Synthetic Biology Open Language (SBOL), a project of the Synthetic Biology Data Exchange Group. SBOL-semantic represents commonly used synthetic biology entities, and its purpose is to improve the distribution and exchange of descriptions of biological parts. In this paper, we describe the data, our methods for transformation to SBPkb, and finally, we demonstrate the value of our knowledgebase with a set of sample queries. We use RDF technology and SPARQL queries to retrieve candidate ``promoter’’ parts that are known to be both negatively and positively regulated. This method provides new web based data access to perform searches for parts that are not currently possible.
Standard for the Electronic Distribution of SBOLv Diagrams
A common method for publicly distributing design diagrams on the Web would enhance understanding of the mechanisms and intended function of synthetic DNA constructs. We aim to improve the usefulness of the depicted design to readers by establishing a systematic scheme for linking diagrams of synthetic biological mechanisms to reference information on the Registry of Standard Biological Parts [1]. Through the use of standard diagrams based on SBOL-visual (BBF RFC 16) symbols, we hope to facilitate communication about synthetic DNA constructs between research groups. This standard applies the use of the established SBOLv symbols on the Web to clearly represent synthetic constructs. Linking these diagrams using http URLs to reference information at the Registry provides a method to retrieve contextual reference information about components of DNA constructs. Use of standardized diagrams in engineering promotes fast and accurate communication between researchers, which in turn promotes effective re-use of biological parts.
A RESTful API for Supporting Automated BioBrick Model Assembly
Constructing simulatable models for BioBricks by hand is a complex and time-consuming task. The time taken could be reduced by using Computer Aided Design (CAD) tools to aid in designing models, but these tools need to be augmented with domain-specific knowledge. Here we propose a standard for a RESTful (Richardson, 2007) API which facilitates the discovery and publication of models of functional biological units. This API is designed to produce parts models which can be automatically combined into complete, simulatable models of entire systems.
Standard for the Electronic Distribution of SBOLv Diagrams
A common method for publicly distributing design diagrams on the Web would enhance understanding of the mechanisms and intended function of synthetic DNA constructs. We aim to improve the usefulness of the depicted design to readers by establishing a systematic scheme for linking diagrams of synthetic biological mechanisms to reference information on the Registry of Standard Biological Parts [1]. Through the use of standard diagrams based on SBOL-visual (BBF RFC 16) symbols, we hope to facilitate communication about synthetic DNA constructs between research groups. This standard applies the use of the established SBOLv symbols on the Web to clearly represent synthetic constructs. Linking these diagrams using http URLs to reference information at the Registry provides a method to retrieve contextual reference information about components of DNA constructs. Use of standardized diagrams in engineering promotes fast and accurate communication between researchers, which in turn promotes effective re-use of biological parts.
A RESTful API for Supporting Automated BioBrick Model Assembly
Constructing simulatable models for BioBricks by hand is a complex and time-consuming task. The time taken could be reduced by using Computer Aided Design (CAD) tools to aid in designing models, but these tools need to be augmented with domain-specific knowledge. Here we propose a standard for a RESTful (Richardson, 2007) API which facilitates the discovery and publication of models of functional biological units. This API is designed to produce parts models which can be automatically combined into complete, simulatable models of entire systems.
Mathematical Modeling: Bridging the Gap between Concept and Realization in Synthetic Biology
Mathematical modeling plays an important and often indispensable role in synthetic biology because it serves as a crucial link between the concept and realization of a biological circuit. We review mathematical modeling concepts and methodologies as relevant to synthetic biology, including assumptions that underlie a model, types of modeling frameworks (deterministic and stochastic), and the importance of parameter estimation and optimization in modeling. Additionally we expound mathematical techniques used to analyze a model such as sensitivity analysis and bifurcation analysis, which enable the identification of the conditions that cause a synthetic circuit to behave in a desired manner. We also discuss the role of modeling in phenotype analysis such as metabolic and transcription network analysis and point out some available modeling standards and software. Following this, we present three case studies—a metabolic oscillator, a synthetic counter, and a bottom-up gene regulatory network—which have incorporated mathematical modeling as a central component of synthetic circuit design.
Mathematical Modeling: Bridging the Gap between Concept and Realization in Synthetic Biology
Mathematical modeling plays an important and often indispensable role in synthetic biology because it serves as a crucial link between the concept and realization of a biological circuit. We review mathematical modeling concepts and methodologies as relevant to synthetic biology, including assumptions that underlie a model, types of modeling frameworks (deterministic and stochastic), and the importance of parameter estimation and optimization in modeling. Additionally we expound mathematical techniques used to analyze a model such as sensitivity analysis and bifurcation analysis, which enable the identification of the conditions that cause a synthetic circuit to behave in a desired manner. We also discuss the role of modeling in phenotype analysis such as metabolic and transcription network analysis and point out some available modeling standards and software. Following this, we present three case studies— a metabolic oscillator, a synthetic counter, and a bottom-up gene regulatory network— which have incorporated mathematical modeling as a central component of synthetic circuit design.
BBF RFC 16: Synthetic Biology Open Language Visual (SBOLv) Specification
Synthetic Biology Open Language Visual (SBOLv) is a graphical notation that supports biological device development. It provides a formal notation for describing the physical composition of basic parts into composite parts during the development of biological devices. It is targeted for use by biological engineers in forward engineering projects. It encourages and supports model-driven engineering.
BBF RFC 16: Synthetic Biology Open Language Visual (SBOLv) Specification
Synthetic Biology Open Language Visual (SBOLv) is a graphical notation that supports biological device development. It provides a formal notation for describing the physical composition of basic parts into composite parts during the development of biological devices. It is targeted for use by biological engineers in forward engineering projects. It encourages and supports model-driven engineering.
TinkerCell: modular CAD tool for synthetic biology
Synthetic biology brings together concepts and techniques from engineering and biology. In this field, computer-aided design (CAD) is necessary in order to bridge the gap between computational modeling and biological data. Using a CAD application, it would be possible to construct models using available biological "parts" and directly generate the DNA sequence that represents the model, thus increasing the efficiency of design and construction of synthetic networks.
TinkerCell: Modular CAD Tool for Synthetic Biology
Synthetic biology brings together concepts and techniques from engineering and biology. In this field, computer-aided design (CAD) is necessary in order to bridge the gap between computational modeling and biological data. Using a CAD application, it would be possible to construct models using available biological “parts” and directly generate the DNA sequence that represents the model, thus increasing the efficiency of design and construction of synthetic networks.
Provisional BioBrick Language (PoBoL)
This BioBricks Foundation Request for Comments (BBF RFC) describes a semantic markup language for publishing and sharing information about BioBricks on the World Wide Web. This BBF RFC includes the recommendation for the minimal information expected when creating a Provisional BioBrick Language (PoBoL) description of BioBricks and for the implementation of the language using Web Ontology Language (OWL).
Provisional BioBrick Language (PoBoL)
This BioBricks Foundation Request for Comments (BBF RFC) describes a semantic markup language for publishing and sharing information about BioBricks on the World Wide Web. This BBF RFC includes the recommendation for the minimal information expected when creating a Provisional BioBrick Language (PoBoL) description of BioBricks and for the implementation of the language using Web Ontology Language (OWL).
BBF RFC 30: Draft of an RDF-based framework for the exchange and integration of Synthetic Biology data
This Request for Comments (RFC) suggests a framework for the description, exchange and interlinking of Synthetic Biology data. The framework would create an open process for the evolution and “rolling” standardization of data models. It describes how data and data models are to be published, how they are exchanged and integrated between different parties, and how they can be extended, corrected and interlinked in a decentralized fashion. These goals are achieved by embracing the RDF (Resource Description Framework), a set of W3C standards. A one-sentence summary of this proposal would there- fore be: “Use RDF according to the W3C standards.” The PoBoL pro ject (Provisional BioBrick Ontology Language, https://web.archive.org/web/20091216100340/http://pobol.org/) is based on this idea. This RFC does not describe a data model per se but only outlines a possible architecture and rules of data exchange.
BBF RFC 30: Draft of an RDF-based Framework for the Exchange and Integration of Synthetic Biology Data
This Request for Comments (RFC) suggests a framework for the description, exchange and interlinking of Synthetic Biology data. The framework would create an open process for the evolution and rolling'' standardization of data models. It describes how data and data models are to be published, how they are exchanged and integrated between different parties, and how they can be extended, corrected and interlinked in a decentralized fashion. These goals are achieved by embracing the RDF (Resource Description Framework), a set of W3C standards. A one-sentence summary of this proposal would there- fore be: Use RDF according to the W3C standards.’’ The PoBoL pro ject (Provisional BioBrick Ontology Language, http://pobol.org) is based on this idea. This RFC does not describe a data model per se but only outlines a possible architecture and rules of data exchange.